| Applications | |
LIS in the era of BDMS, distributed and cloud computing: Is it time for a complete redesign?
In this paper, we present the main features of a new class of emerging DBMSs, namely NoSQL and NewSQL, from the data management perspective with a particular focus on distributed computing and share-nothing architecture |
 |
|
Abstract
For over four decades, traditional relational database management systems (DBMS) have been the leading technology for data storage, retrieval and management. However, they were designed in a different hardware and software era and are facing challenges in meeting the performance and scale requirements of distributed data-intensive applications, including Big Data. These traditional database management systems are not designed to take advantage of distributed and cloud computing. They support vertical (scale-up) rather than horizontal (scale-out) scalability, which is more common in distributed systems and applications. Due to increasing needs for scalability and performance, alternative systems have emerged: NoSQL and NewSQL database management systems.
Distributed computing and sharenothing architecture became very popular during the last decade. At the same time, cloud computing has emerged as a computational paradigm for ondemand network access to a shared pool of computing resources. Proliferation of open-source and commercial distributed data management systems and cloud computing platforms makes building distributed, data-intensive applications and systems in the land administration domain easier than ever before.
In this paper, we present the main features of a new class of emerging DBMSs, namely NoSQL and NewSQL, from the data management perspective with a particular focus on distributed computing and share-nothing architecture. We also briefly present a simple taxonomic classification of DBMSs for choosing a DBMS in building land information systems (LIS) and applications, and two LIS prototypes built on NoSQL BDMS and NewSQL DBMS.
Introduction
The majority of the existing land information systems (LIS) are dominantly online transaction processing (OLTP) systems, built on mission-critical (object-) relational database management systems (DBMSs) such as Oracle, Microsoft SQL Server, IBM DB2, MySQL, and PostgreSQL. Modern general-purpose OLTP database systems include a standard suite of features: a collection of on-disk data structures for storing relational tables row-by-row, heap files and B-trees for indexing, support for multiple concurrent queries via locking-based concurrency control and ACID1 transaction properties, log-based recovery, and an efficient buffer manager. These features were developed to support transaction processing in the 1970’s and 1980’s, when an OLTP database was many times larger than the main memory, and when the computers that ran these databases cost hundreds of thousands to millions of dollars (Stonebraker & Cetintemel, 2018).
All these systems were architected when hardware characteristics were much different than today: (i) processors are thousands of times faster; (ii) memories are thousands of times larger; and (iii) disk volumes have increased enormously. However, the bandwidth between disk and main memory has increased much more slowly. Surprisingly, this relentless pace of technology didn’t dramatically affect the architecture of database systems – the architecture of most DBMSs is essentially identical (Stonebraker, et al., 2007). Furthermore, database has been the least scalable component in application architectures. In general, the last four decades of DBMS development could be summarized as “one size fits all”, reflecting the fact that the traditional DBMS architecture has been used to support data-intensive applications in different domains and with widely varying capabilities and requirements.
The modern computing environment is largely distributed – enterprises and institutions have geographically distributed and interconnected data centers, forming distributed systems. However, traditional DBMS are not designed to take advantage of distributed and cloud computing. They only support vertical (scale-up) rather than horizontal (scale-out) scalability, which is more common in distributed systems and applications. What’s needed is a DBMS that scales-out linearly and limitlessly by adding new commodity servers to a shared-nothing DBMS cluster.
Land administration (LA) agencies often throw additional CPUs and memory at database servers to get more power from these systems. Standard approaches to vertical scalability are costly, requiring expensive hardware and DBMS upgrades, and also add development complexity, and increase overhead and maintenance costs. The crucial problem with vertical scalability is that the cost growth is not linear: a machine with double as many CPUs, RAM and disk capacity as another, usually costs much more than double as much, but can’t handle double the workload. Therefore, this architecture makes it complicated to build distributed databases that deliver the expected resilience, consistency and maintainability.
The work presented in (Bennett, Pickering, & Sargent, 2018) and (Bennett, Pickering, & Sargent, 2019) is one of the first systematic and comprehensive research synthesis that was undertaken to get a global review of the uptake and impact of non-relational DBMS and blockchain on the land administration sector. The authors found that recent developments in data management technologies and systems appear to be under-exploited within the LA domain. They correctly concluded that whilst uptake of nonrelational DBMS and distributed DBMS is occurring, scaled uptake is much slower than anticipated, and to a significantly lesser degree than in other sectors.
In this paper, we go one step further and present the main features of a new class of emerging DBMSs, from the data management perspective with a particular focus on distributed computing/systems and share-nothing architecture. Distributed computing/systems2 and share- nothing architecture became very popular during the last decade, including many Big Data processing platforms/frameworks with scalability and fault tolerance capabilities. They use large amounts of commodity hardware to store and analyze big volumes of data in a highly distributed, scalable and cost-effective way. These new systems are also optimized for massive parallel data intensive computations (Apache Hadoop (Apache Software Foundation, 2019), Apache Spark (Apache Software Foundation, 2018), Apache Flink (Apache Software Foundation, 2019)) including their extensions and adaptations for spatial and spatio-temporal domain (SpatialHadoop (Eldawy & Mokbel, 2015), GeoSpark (Yu, Zhang, & Sarwat, 2019), MobyDick (Galić, Mešković, & Osmanović, 2017)). This approach is followed by essentially all high-performance, scalable, DBMSs, as well as by the leading cloud service providers: Amazon (DynamoDB), Google Cloud Platform (Spanner) and Microsoft (Azure Cosmos DB).
The rest of the paper is structured as follows. In Section 2 we discuss the main tradeoffs, issues and challenges in traditional DBMSs and blockchain. Section 3 discusses the CAP theorem and its impact on the emergence of NoSQL and NewSQL databases. Section 4 presents a simple taxonomic classification of DBMSs that can be applied for selecting a DBMS in designing and building land administration systems and applications. An overview of cloud computing models and related cloud services are presented in Section 6. In Section 5, we shortly describe our two LIS prototypes based on a BDMS and NewSQL DBMS. Section 7 concludes the paper and discusses future directions.
Traditional DBMS and blockcahin – Tradeoffs, issues and challenges
Traditional DBMSs
Traditional disk-based DBMSs have four sources of processing overhead which limit their scalability (Harizopoulos, Abadi, Madden, & Stonebraker, 2008):
• Write-ahead logging – Traditional DBMSs write everything twice; once to the database and once to the log. Moreover, the log must be forced to disk to guarantee transaction durability. Therefore, logging is an expensive operation.
• Locking – Before touching a record, a transaction must set a lock on it in the lock table. This is an overhead-intensive operation.
• Latching – Updates to shared data structures (e.g. B-trees, the lock table and resource tables) must be done carefully in multi-threaded environment. Typically, this is done with short-duration latches, which are another substantial source of overhead.
• Buffer Management – Data in traditional DBMSs is stored on fixed-size disk pages. A buffer pool manages which set of disk pages is cached in memory at any given time. Moreover, records must be located on pages and the field boundaries identified. Again, these operations are overhead- intensive.
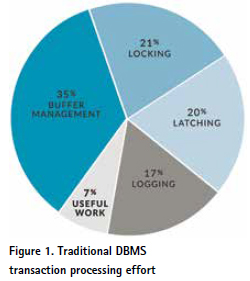
Figure 1 shows the breakdown of instruction count for various DBMS processing components for a transaction from TPC-C3. It shows the 93 percent overhead built into a typical traditional/ legacy DBMS, and only 7 percent of machine resources dedicated to the task at hand. Designed primarily for data integrity goals, these overheads prevent traditional DBMSs from scaling to meet big data volumes and workloads.
The limited scalability and availability of the traditional (share-everything and share-disk) database architectures that has been used in the cloud is caused by a traditional 3-tier architecture: web clients access a data center that features a load balancer, Web application servers, and database servers. The data center typically uses a shared-nothing cluster, as the most effective solution for the cloud. For a given application, there is one database server that runs a DBMS and provides fault-tolerance and data availability through replication. As the number of Web clients increases, it is a relatively easy to add Web applications servers/ machines to take over incoming load and scale up. However, the database server become the bottleneck – adding new database servers would require replicating the entire database, which would take much time (Öszu & Valduriez, 2020).
Blockchain
Blockchain has become a hot, polemical topic, subject to much hype (Ito, Narula, & Robleh, 2017) and criticism (Roubini, 2018). Most of the initial contributions have been made by developers and companies, outside of academic world – academic research on blockchain has recently started. It is popular topic in modern distributed transaction processing, and more recently there has been a growing interest in the database research community to reconcile DBMSs and blockchain paradigms and technologies.
BlockchainDB (El-Hindi, Binnig, Arasu, Kossmann, & Ramamurthy, 2019) leverages blockchains as a storage layer and introduces a database layer on top that extends blockchains by classical data management techniques (e.g., sharding) as well as a standardized query interface to facilitate the adoption of blockchains for data sharing use cases. By introducing the additional database layer, the performance and scalability when using blockchains for data sharing can be improved and the complexity for organizations intending to use blockchains for data sharing can be massively decreased.
Blockchain relational database (Nathan, Govindarajan, Saraf, Sethi, & Jayachandran, 2019) is a blockchain platform built on top of DBMS, where block ordering is performed before transaction execution and transaction execution happens in parallel without prior knowledge of block ordering.
ChainSQL (Muzammal, Qu, & Nasrulin, 2018), is an open-source system developed by integrating the blockchain with the database, i.e. a blockchain database application platform that has the decentralized, distributed and audibility features of the blockchain and quick query processing and welldesigned data structure of the distributed databases.
ChainSQL features a tamperresistant and consistent multi-active database, a reliable and cost-effective data-level disaster recovery backup and an auditable transaction log mechanism.
Fabric++ (Sharma, Schuhknecht, Agrawal, & Dittrich, 2018) is the performance enhancement of Hyperledger Fabric4, towards blurring the conceptual lines between blockchain and distributed DBMSs. It is achieved by (i) identifying similarities of the transaction pipeline of contemporary blockchain systems and distributed DBMSs and (ii) by transition of distributed DBMSs technology to the transaction pipeline of Hyperledger Fabric. Fabric++ outperforms the Hyperledger Fabric in terms of throughput of successful transactions by up to factor 3x, while keeping the scaling capabilities intact.
However, despite all the hype around the blockchain technology, many of the challenges that blockchain systems have to face are de facto fundamental transaction management problems. The main problem lies in Byzantine fault tolerance: while distributed DBMSs require a trusted set of participants/nodes, blockchain systems are able to deal with a certain number of malicious participants/nodes. Unfortunately, ensuring the Byzantine fault tolerance over all nodes heavily complicates transaction processing: if any node of the network is considered to be potentially malicious, a complex consensus mechanism is required to ensure the integrity of the blockchain system (Sharma, Schuhknecht, Agrawal, & Dittrich, 2018). Under this model, the overhead of concurrency control is much higher. As a consequence, the blockchain is still not being used as a shared database in many real-world OLTP applications. There are two important reasons for this:
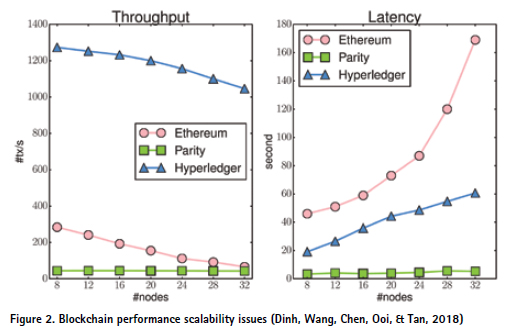
1. A major blockchain obstacle is its limited scalability and performance. Recent benchmarks results (Dinh, Wang, Chen, Ooi, & Tan, 2018) demonstrate several tradeoffs in the blockchain design that causes big performance gaps between blockchain and DBMSs. The state-ofthe- art blockchain systems5 can only achieve 100s or maximally 1000s of transactions per second (Figure 2), which is often way below the requirements of modern OLTP systems and applications, and also far below what state-of-the-art DBMSs can offer.
2. Blockchain lacks high-level abstractions such as SQL as well as other transactional guarantees like well-defined consistency levels. Similar to NoSQL DBMS, state-of-the-art blockchain systems have proprietary, low-level programming interfaces (aka smart contract language) and require application developers to know about the internals of a blockchain to decide on the visibility of updates, which radically reduces developers’ productivity.
As confirmed in (Dinh, Wang, Chen, Ooi, & Tan, 2018), the current state-of-the-art blockchain systems are not yet ready (and may never be ready) for mass usage, and there is no other well- established application domain beside crypto-currency. They perform poorly at data-intensive processing tasks being efficiently handled by DBMSs and the performance gap is still too big for blockchains to be disruptive to state-of-the-art distributed and share-nothing DBMSs.
CAP theorem – Its reflections and impact on NoSQL and NewSQL DBMS
Replication is a fundamental concept of distributed systems for achieving availability and scalability – it involves creating and distributing copies of data, as well as ensuring copies remain consistent. Modern distributed data-intensive OLTP applications and systems replicate data across geographically diverse locations to (i) enable trust decentralization; (ii) guarantee low-latency access to data; and (iii) provide high availability even in the face of node and network failures.
The ultimate goal of a distributed system is seemingly simple – it should ideally be just a fault- tolerant and more scalable version of a centralized system. A distributed system should maintain the simplicity of use of a centralized system, leverage distribution and replication to boost availability by masking failures, provide scalability and/or reduce latency, and its consistency (Viotti & Vukolić, 2016).

Recently, there has been considerable renewed interest in the CAP theorem (Brewer, 2000) for database management system (DBMS) applications that span multiple processing nodes. In brief, this theorem states:
i. There are three properties that could be desired by DBMSs:
▪ C: Consistency. The goal is to allow multisite transactions to have the familiar all-or-nothing semantics, commonly supported by commercial DBMSs. In addition, when replicas are supported, one would want the replicas to always have consistent states.
▪ A: Availability. The goal is to support a DBMS that is always up. In other words, when a failure occurs, the system should keep going, switching over to a replica.
▪ P: Partition tolerance. If there is a network failure that splits the processing nodes into two groups that cannot talk to each other, then the goal would be to allow processing to continue in both subgroups.
ii. Any distributed system can have at most two of these three properties (Figure 2).
The CAP theorem6 famously states that it is impossible to guarantee both consistency (C) and availability (A) in the event of a network partition (P). Since network partitions7 are always theoretically possible in a distributed system, the modern DBMSs fracture into two paradigms:
▪ NoSQL that prioritized A (availability) – aka AP DBMS
▪ NewSQL that prioritized C (consistency) – aka CP DBMS
In other words, the way how a DBMS handles failure determines which elements of the CAP theorem they support:
▪ NoSQL DBMSs provide mechanisms to resolve conflicts after nodes are reconnected
▪ NewSQL DBMSs stop allowing updates until a majority of nodes are reconnected
In general, consistency refers to the ability of a DBMS to ensure that it complies to a predefined set of rules. However, the set of rules implied by ACID and CAP are totally different – in ACID, the rules refer to application-defined semantics, whereas the C of CAP refers to the rules related to making a concurrent, distributed system appear like a single-threaded, centralized system (Abadi, 2019).
In the NoSQL community, the CAP theorem has been used as the justification for giving up consistency (C). Since most NoSQL systems typically disallow transactions that cross a node boundary, then consistency applies only to replicas. Therefore, this theorem is used to justify giving up consistent replicas and replacing it with “eventual consistency”. With this relaxed approach, NoSQL DBMS guarantees that all replicas will converge to the same state eventually, i.e., when network connectivity has been re-established and enough subsequent time has elapsed for replica cleanup. The justification for giving up consistency (C) is such that the availability (A) and partition tolerance (P) can be preserved. Although eventual consistency enables high availability, it significantly increases application complexity to handle inconsistent data.
NoSQL8
As we have seen, the CAP theorem asserts that any networked shared-data system can have only two of three desirable properties. However, by explicitly handling partitions, designers can optimize consistency and availability, thereby achieving some tradeoff of all three. Consequently, designers and researchers have used the CAP theorem as a reason to explore a wide variety of novel distributed systems. The NoSQL vendors also have applied it as an argument against traditional DBMSs (Brewer, 2012). They argued that SQL and transactions were limitations to achieving the high performance needed in modern operational, online transaction processing (OLTP) applications. NoSQL systems forego the ACID (Atomicity, Consistency, Isolation, Durability) guarantees of traditional DBMSs and SQL in exchange for ability to scale out (horizontally) and availability.
However, relaxing or omitting transaction support and eliminating SQL, result in moving back to a low-level DBMS programming interface. Replacing standard ACID with eventual consistency or omitting it completely, pushes consistency problems into the application logic where they are much more difficult to solve and manage (Stonebraker, 2012). Application developers are de facto forced into handling the eventual consistency of NoSQL systems – consequently, NoSQL could be translated into “lots of work for the application” (Abadi, 2018).
As already stated, the key feature of NoSQL systems is that they sacrifice ACID transactional guarantees and the (object-) relational model of traditional DBMSs in favor of eventual consistency (ACID lite) and other data models (e.g., key/ value, graphs, documents). The two most well-known systems that first followed the NoSQL paradigm are BigTable and Dynamo, followed by their open source clones Cassandra, Riak and HBase, as well as CouchDB and MongoDB. At that time, it was believed that the advantage of using a NoSQL system was to allow developers focusing on the application development, rather than having to worry about how to scale the DBMS.
However, CAP theorem doesn’t impose system restrictions in the baseline case. Therefore, it is wrong to assume that DBMSs that reduce consistency (in the absence of any network partitions) are doing so due to CAP-based decisionmaking. In fact, CAP allows the DBMS to make the complete set of ACID guarantees alongside high availability when there are no network partitions (Abadi, 2012). Therefore, the CAP theorem does not fully justify the default configuration of NoSQL system that reduces consistency, as well as some other ACID guarantees.
NoSQL DBMS are also referred as BASE systems – Basically Available, Soft state, and Eventually consistent (Pritchett, 2008). Basically Available means that the database is available all the time whenever it is accessed, even if parts of it are unavailable; Soft-state highlights that it does not need to be consistent always and can tolerate inconsistency for a certain time period; and Eventually consistent means that while a database may have some inconsistencies at any point in time, it will eventually become consistent when all updates cease
Consequently, both NoSQL vendors and system integrators recognized that NoSQL systems cause application developers to spend too much time on writing code to handle inconsistent data and that ACID transactions increase developers’ productivity. Thus, the only option was to purchase a more powerful singlenode machine to scale the DBMS up vertically, and to develop the proprietary middleware that supports transactions. Both approaches are very expensive, and this fact actually triggered the design and development of the NewSQL systems (Pavlo & Aslett, 2016). Therefore, it is not a surprise that many mission-critical enterprises applications, including LISs, have not been able to use NoSQL systems simply because they cannot give up strict transactional and consistency requirements.
NewSQL
The fact that it is extremely difficult to build bug-free applications over NoSQL DBMSs that do not guarantee the strict consistency has resulted in many recently released systems claiming to guarantee C (consistency) and be CP systems. The list of newer systems includes: Cloud Spanner, CockroachDB, FaunaDB, MemSQL, NuoDB, TiDB, VoltDB and YugaByteDB (Abadi, 2018). These systems (and some others, not listed here) preserve SQL and offer high performance and scalability, while preserving the traditional ACID transactions (C in CAP). To distinguish them from the traditional DBMSs and NoSQL, this class of systems is termed as “New SQL”. Such systems are equally capable of high throughput as the NoSQL for OLTP read-write workloads, guarantee ACID transactions, eliminate the need for applicationlevel consistency code and preserve the relational model including high-level language query capabilities of SQL.
There are three important reasons for the next generation of LISs to be NewSQL-based (CP), instead of NoSQL-based (AP) systems:
i. NoSQL systems fail to guarantee consistency and result in complex, expensive to develop and maintain, and (often) buggy application code. ii. The availability reduction that is sacrificed to guarantee consistency in NewSQL systems is extremely small, and hardly noticeable for many applications, including LIS.
iii. The CAP theorem is fundamentally asymmetrical: NewSQL systems guarantee consistency, whereas NoSQL systems do not guarantee availability9.
Therefore, we believe that the next generation of LISs will remain the OLTP systems, based on a NewSQL DBMS with the following features (Stonebraker, 2012):
i. SQL as the primary mechanism for application interaction.
ii. Strong consistency, i.e. ACID support for transactions.
iii. A nonlocking concurrency control mechanism – realtime reads will not conflict with writes and thereby cause them to stall.
iv. An architecture providing much higher per-node performance than available from the traditional DBMS.
v. A share-nothing architecture10 capable of running on a large number of commodity hardware/machinesA
vi. Automatic replication.
Although primarily designed to support the transactional workloads in enterprise applications (like LISs), NewSQL DBMSs have had a relatively slow rate of adoption, especially compared to the developer-driven NoSQL uptake. The main reason for the relatively slow rate is the fact that decisions regarding DBMS choices for enterprise applications are more conservative than for non- transactional workloads in new Web application (Pavlo & Aslett, 2016). Regrettably, and as already mentioned in (Bennett, Pickering, & Sargent, 2019), scaled uptake in the LA/LIS domain is occurring slower than anticipated, and to a lesser degree than in other sectors.
Comparison of traditional, NoSQL and NewSQL DBMS
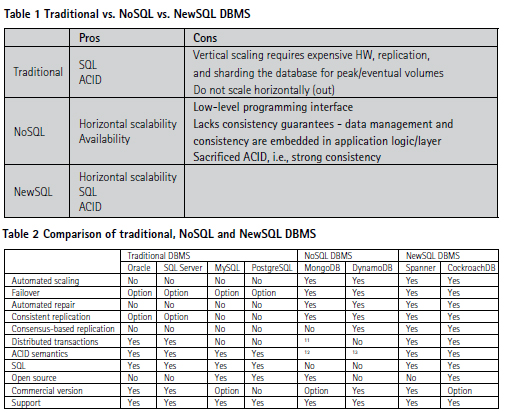
Table 1 shows the fundamental differences between traditional, NoSQL and NewSQL DBMS. An additional comparison of the important characteristics of the typical DBMS systems for each DBMS class is shown in Table 2.
▪ Automatic scaling – automatic and continuous rebalancing of data between the nodes of a cluster.
▪ Automated failover – uninterrupted availability of data through small-scale and largescale failures, i.e., from server restarts to data center outages.
▪ Automated repair – automated repair of missing data after failures, using unaffected replicas as sources.
▪ Strongly consistent replication – once transaction is committed, all reads are guaranteed to see it.
▪ Consensus-based replication – guarantee that progress can be made as long as any majority of nodes is available.
▪ Distributed transactions – correctly committed transactions across a distributed cluster, whether it’s a few nodes in a single location or many nodes in multiple data centers.
▪ ACID semantics – every transaction provides atomicity, consistency, isolation and durability.
▪ Eventual consistent reads – optionally reading from replicas that do not have the most recently written data.
▪ SQL – high-level DBMS programming interface.
▪ Open source – source code is freely available.
▪ Commercial version – enterprise version available to paying customers.
▪ Support – either limited (free, community-based) or full (paid, 24/7 support).
Table 2 doesn’t pretend to be an exhaustive comparison of traditional, NoSQL and NewSQL DBMS, i.e., their capabilities and features – it’s rather a general overview of some significant differences and facts relevant for designing and building a new generation of data-intensive applications and systems, especially in the context of distributed and cloud computing. It would be also unfair to conclude that traditional DBMS should not be considered any more in building a new generation of LIS – they are suitable, proven and mature technology in case of shareeverything or share-disk architecture and for on-premise, single data center environments. However, traditional DBMS fail to adapt to the distributed, less predictable and high-volume workloads in the cloud deployments.
Also, NewSQL DBMS should not be considered as a panacea for building LIS and other relevant data-intensive applications and systems in the LA domain – these systems/applications should be primarily designed and implemented as (i) resilient14; (ii) scalable and (iii) maintainable. Resilient systems/ applications continue to work correctly even in the face of hardware faults, software faults or human errors. As data volume, traffic volume or complexity grows, they should be scalable, i.e., to be able to cope with increased workload. Maintainable systems are operable, simple and extensible (Kleppmann, 2017) – they are simply a prerequisite for sustainability. It should be emphasized that simplicity doesn’t necessary mean reduction of system/application functionality – it means removing accidental complexity, i.e., complexity not inherent in the domain problem, but complexity that arises primarily from the implementation (Ben & Marks, 2006), (Brooks, 1987).
Choosing a DBMS in the LA domain
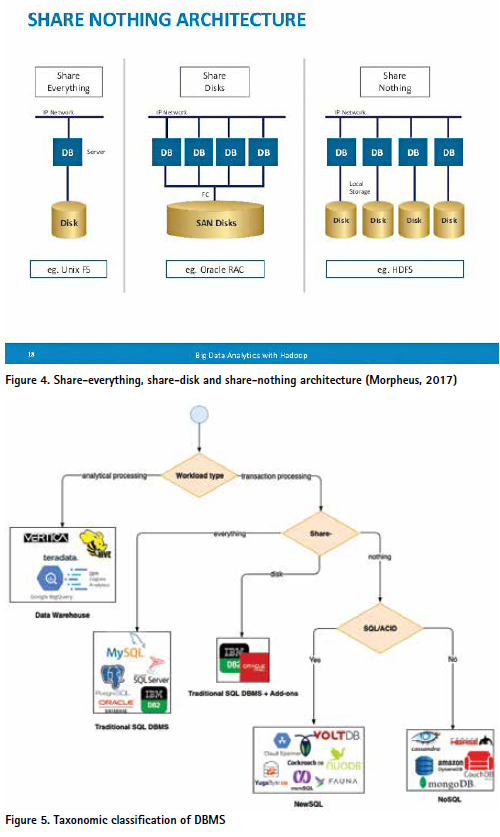
Generally, a DBMS can run on three types of architectures:
i. Share-everything – the DBMS runs on a single machine consisting of a collection of cores sharing a common main memory and disk system. IBM DB2, Microsoft SQL Server, MySQL, Oracle and PostgreSQL are typical DBMSs running on this architecture.
ii. Share-disks – the DBMS runs on several machines with independent CPUs and RAM, but stores data on disk cluster that is shared between machines, which are connected via a fast network15. IBM DB2 pureScale and Oracle RAC are typical examples of a DBMS running shared disk cluster.
iii. Share-nothing – each (virtual) machine running the database is called a node. Each node uses its CPUs, RAM and disks independently, and the nodes in a collection of self-contained nodes are connected to one another through networking. CockroachDB (CockroachDB, 2018), FaunaDB (Fauna, Inc., 2019), Google Spanner (Google, Inc., 2019),
VoltDB (VoltDB, Inc., 2019), NuoDB (NuoDB, Inc., 2019) and YugaByte (YugaByte, Inc., 2016-2019) are NewSQL/NoSQL systems running on share-nothing architecture.
When selecting the right DBMS in building and developing the information systems in the LA domain there are three important criteria to consider (Figure 5):
1. Workload type
a. Operational database (online transaction processing – OLTP)
b. Analytical database (online analytical processing – OLAP)
3. SQL and ACID transactions
4. Architecture
a. Distributed share-nothing architecture (horizontal scaling, aka scale-out)
b. Share-everything or sharedisk architecture (vertical scaling, aka scale-up)
Figure 5 shows a simple taxonomic classification of DBMSs based on these three criteria that can be applied in selecting the right DBMS in the LA domain. It also includes typical DBMS products for each class.
Cloud computing
In the recent years, cloud computing has emerged as a computational paradigm for on-demand network access to a shared pool of computing resources (e.g., network, servers, storage, applications, and services) that can be rapidly provisioned with minimal management effort or service provider interaction. Overall, a cloud computing model aims to provide benefits in terms of lesser up-front investment, lower operating costs, higher scalability, elasticity, easy access through the Web, and reduced business risks and maintenance expenses. It offers three key features:
1. Unlimited distributed computing power
2. Unlimited data storage
3. The ability to harness these only as needed – paying only for the consumed resources, rather than buying the resources that might be needed at peak.

Due to such features of cloud computing, many applications and systems have been deployed in the cloud over the last few years. Traditionally, most LA agencies have been purchasing and using on-premise enterprise/legacy IT infrastructure – their IT departments have been managing and maintaining complete IT infrastructure (data center, networking, storage servers, and virtualization), platform (operating systems, databases, security) and all applications (Figure 6). Cloud computing offers three service models (NIST, 2011):
Infrastructure as a Service (IaaS). The capability provided to the consumer is to provision processing, storage, networks, and other fundamental computing resources where the consumer is able to deploy and run arbitrary software, which can include operating systems and applications. The consumer does not manage or control the underlying cloud infrastructure but has control over operating systems, storage, and deployed applications; and possibly limited control of selected networking components.
Platform as a Service (PaaS). The capability provided to the consumer is to deploy onto the cloud infrastructure consumer-created or acquired applications created using programming languages, libraries, services, and tools supported by the provider. The consumer does not manage or control the underlying cloud infrastructure but has control over the deployed applications and possibly configuration settings for the application-hosting environment.
Software as a Service (SaaS). The capability provided to the consumer is to use the provider’s applications running on a cloud infrastructure. The applications are accessible from various client devices through either a thin client interface (e.g. web browser), or a program interface. The consumer does not manage or control the underlying cloud infrastructure.
According to (Gartner, Inc., 2019), 75 percent of all databases will be deployed or migrated to a cloud platform by the end of 2022. DBMS cloud services are already $10.4 billion of the $46.1 billion DBMS market in 2018. The overall DBMS market grew at 18.4 percent from 2017 to 2018 (the best growth in over a decade) and cloud DBMS accounted for 68 percent of that growth. This trend reinforces that cloud computing infrastructures and the services that run on them are becoming the new data management platform.
Database as a service (DBaaS) has emerged as a subclass of Software as a Service (SaaS)16 – it is regulated by the same principles as SaaS and delivers the functionalities of a database management system in the cloud. However, cloud computing imposes new requirements to data management – a cloud DBMSs (either managed 17or cloud-native 18) shall have the following capabilities (Grolinger, Higashino, Tiwari, & Capret, 2013):
• Scalability and high performance – today’s systems and applications are experiencing continuous growth in terms of the data they need to store, the users they must serve, and the throughput they should provide;
• Elasticity – as cloud systems/ applications can be subjected to enormous fluctuations in their access patterns;
• Ability to run on commodity heterogeneous servers – as most cloud environments are based on them;
• Fault tolerance – given that commodity machines are much more prone to fail than high- end servers;
• Security and privacy features – because the data may be stored on third-party premises on resources shared among different tenants;
• Availability – as critical systems/ applications have also been moving to the cloud and cannot afford extended periods of downtime.
BDMS- and NewSQLbased LIS prototypes
In this section, we briefly outline two LIS prototypes we are developing at the University of Zagreb, Faculty of Electrical Engineering and Computing. Both protypes implements a reference Land Administration Data Model (ISO, 2012) and a small set of generic CRUD operations and spatial queries.
AsterixDB-based LIS prototype
Apache AsterixDB (Alsubaiee, et al., 2014) is a highly scalable big data management system (BDMS) that aims to support ingesting, storing, indexing, querying and managing semi-structured data. It was co-developed as a research system19 by the teams of University of California Irvine and University of California Riverside, with the goal to combine the best ideas from the parallel DBMS, Apache Hadoop (Apache Software Foundation, 2019), and the semi-structured data models (e.g., XML/JSON) in order to create a next-generation BDMS. Apache AsterixDB core features include (Apache Software foundation, 2016):
• A semi-structured NoSQLstyle data model based on JSON extended with ODBMS concepts.
• Two declarative query languages for querying semi-structured data.
• Apache Hyracks runtime query execution engine, for partitionedparallel execution of query plans.
• Support for querying external data (e.g., in HDFS) as well as data stored within AsterixDB.
• A rich set of primitive data types, as well as OGC support for spatial data20.
• Indexing options that include B+ trees, R trees, and inverted keyword index types.
• Basic transactional (concurrency and recovery) capabilities akin to those of a NoSQL.
The availability of two declarative query languages, namely AQL and SQL++ (Ong, Papakonstantinou, & Vernoux, 2015), strongly distinguish Apache AsterixDB from the most NoSQL DBMS, therefore classifying it as Not only SQL BDMS.
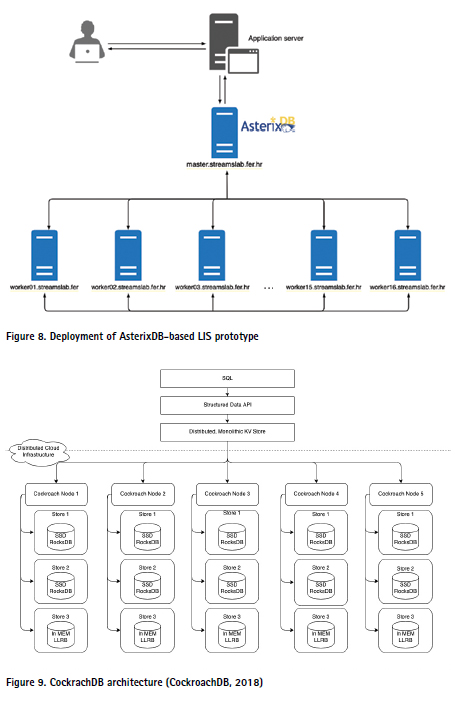
Figure 8 shows the deployment of our AsterixDB-based LIS prototype on a computer cluster consisting of 16 workers (each with 8 CPU cores, 16 GB RAM, 1TB HDD and Linux OS), which is available in our Data Streams Laboratory21.
CockroachDB-based LIS prototype
CockroachDB (Cockroach Labs, 2019) is a cloud-native, distributed DBMS (i.e., CP system according to the CAP theorem), primarily designed for (i) horizontal scalability; (ii) strong consistency and (iii) disaster resilience (survivability). Disaster resilience aims to tolerate disk, machine, rack, and even data center failures with minimal latency disruption and without manual intervention. It is an open source derivate of Google Spanner22(Google, Inc., 2019), built on top of RocksDB (Facebook, Inc., 2019) distributed key/ value storage engine, and can be deployed on and across any public or private cloud23 as fully managed version.
CockroachDB implements a layered architecture (Figure 9). The highest level of abstraction is the SQL layer, which provides standard concepts such as schemas, tables, columns, and indexes. The SQL layer in turn depends on the distributed key-value store, which handles the details of range addressing to provide the abstraction of a single, monolithic keyvalue store. The distributed key- value store communicates with any number of physical CockroachDB nodes, with each node containing one or more stores, one per physical device (CockroachDB, 2018). The CockroachDB-based LIS prototype is being developed using Go programming language (Google, Inc., 2019) and GORM object-relational mapping library (Jinzhu, 2019). Built on CockroachDB, it is well suited for the cloud computing era and cloud deployment, including Docker containerization (Docker, Inc., 2019) and Kubernetes orchestration (Linux Foundation, 2019). Figure 10 shows the deployment of our LIS prototype on 5 CockroachDB nodes, each with 8 CPU cores, 16 GB RAM, 1TB HDD and Linux OS.
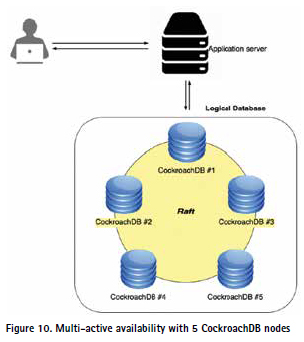
Through multi-active availability replication (Figure 10), where each node in the cluster performs read and write operations without generating conflicts and/or anomalies, our LIS prototype ensures strong consistency, high availability and outstanding resilience. CockroachDB can handle up to F node failures, where the replication factor N = 2F + 1; therefore, our prototype deployment environment can handle up to 2 node failures. Raft consensus algorithm (Ongaro & Ousterhout, 2014) ensures that a majority of the data’s replicas are identical, and a minority of nodes can be down without stopping the database from making progress.
Conclusions
The majority of the existing LIS are predominantly online transaction processing (OLTP) systems, built on (object-)relational database management systems. These traditional database management systems are not designed to take advantage of distributed and cloud computing. They only support vertical (scale-up) rather than horizontal (scale-out) scalability, which is more common in distributed systems and applications.
Blockchain is one of the hottest topics in contemporary distributed transaction processing. However, despite all the hype around the blockchain technology, many of the tradeoffs, issues and challenges that blockchain systems espouse are yet to be resolved. They perform poorly at data- intensive OLTP tasks and the performance gap between them and DBMSs is still too big for blockchains to be disruptive to state-of-the-art distributed DBMSs. Improving blockchain performances by introducing distributed DBMSs designs into blockchain, including a high-level SQL interface, seems like a promising approach, but there is still a long way to go.
Distributed computing systems and shared-nothing architecture became very popular during the last decade, including new data processing platforms/ frameworks with scalability and fault tolerance capabilities. These new systems/frameworks use large amounts of commodity hardware to store, manage and analyze data in a highly distributed, scalable and cost-effective way.
The key feature of NoSQL systems is that they sacrifice ACID transactional guarantees and the (object-) relational model of traditional DBMSs in favor of eventual consistency and other data models (e.g., key/value, graphs, documents). This is because it was believed that these aspects of existing DBMSs inhibit their ability to scale horizontally and achieve the high availability. However, many mission-critical enterprises applications, including LIS, are not able to use NoSQL systems simply because they cannot give up strict transactional and consistency requirements.
For OLTP systems with the potential for massive scale, NewSQL DBMSs provide a compelling solution with potential throughput that reaches millions of transactions per second. Although primarily designed to support the ACID-transactional workloads in enterprise applications and systems, NewSQL DBMSs have had a relatively slow rate of adoption in the LA domain. Data- intensive OLTP applications and systems, including LIS, should be primarily designed and implemented as resilient, scalable and maintainable systems that guarantee consistency, built on the “invest in data/system resilience, not disaster recovery” paradigm. NewSQL DBMSs are designed and developed exactly for these purposes, and LIS system/ software architects should seriously consider NewSQL DBMS, distributed and cloud computing in designing, building and deploying the next generation of LIS. We also advocate that the next generation of LIS should remain data-intensive OLTP systems built on SQL/ACID standards, NewSQL DBMS and gain effectiveness from distributed and cloud computing as new LIS data management platforms.
Acknowledgment
The author would like to thank his postgraduate students Natko Bišćan and Mario Vuzem for their engagement and great work in implementing two presented prototypes.
Endnotes
1Atomicity, Consistency, Isolation, Durability – a set of properties of database transactions that guarantee validity.
2A distributed system is a collection of autonomous computing elements (nodes) that appears to its users as a single coherent system (van Steen & Tanenbaum, 2017).
3On-line transaction processing (OLTP) benchmark.
4An open-source permissioned blockchain system (https://github. com/hyperledger/fabric)
5Ethereum, Parity and Hyperledger
6There has been a lot of academic debate on CAP confusion and misleading interpretation – interested readers can refer to (Brewer, CAP Twelve Years Later: How the “Rules” Have Changed, 2012), (Abadi, Consistency Tradeoffs in Modern Distributed Database System Design: CAP is Only Part of the Story, 2012), (Kleppmann, A Critique of the CAP theorem, 2015) and (Mahajan, Alvisi, & Dahlin, 2011) for more details.
7A network partition refers to a situation where one part of the network is cut off from the rest due to a network fault.
8NoSQL community claims that NoSQL should be interpreted as “Not only SQL”, because some systems support high-level SQL-like languages.
9No system can guarantee 100% availability.
10Sometimes called horizontal scaling or scaling out.
11Multi-document transactions
12Document-only
13Row-only; distributed transactions and ACID semantics across all data in the database requires an additional library.
14aka fault-tolerant, reliable.
15SAN (Storage Area Network)
16Oracle Cloud Platform (OCP) offers DBaaS as a subclass of PaaS.
17No significant modification to the DBMS to be “aware” that it is running in a cloud environment.
18DBMS is designed explicitly to run in a cloud environment.
19Couchbase Analytics uses Apache AsterixDB as the storage and parallel query engine.
20https://github.com/apache/asterixdb/ commit/ 8cc882538af1e74cc1f 92eb42d24d76370384279 21
21https://streamslab.fer.hr
22But without the hardware infrastructure upon which Spanner relies at Google.
23Cockroach Cloud is available on Google Cloud and AWS (Amazon Web Services).
References
Abadi, D. (2012). Consistency Tradeoffs in Modern Distributed Database System Design: CAP is Only Part of the Story. IEEE Computer, 45(2), 37-42.
Abadi, D. (2018, September 21). NewSQL database systems are failing to guarantee consistency, and I blame Spanner. Retrieved March 18, 2019, from NewSQL database systems are failing to guarantee consistency, and I blame Spanner: http://dbmsmusings. blogspot.com/2018/09/newsqldatabase- systems-are-failing-to.html
Abadi, D. (2019, July 25). Overview of Consistency Levels in Database Systems. Retrieved August 8, 2019, from http://dbmsmusings.blogspot.com
Alsubaiee, S., Altowim, Y., Altwaijry, H., Behm, A., Borkar, V., Bu, Y., . . . Li, C. (2014). AsterixDB: A Scalable, Open Source BDMS. PVLDB, 7(14), 1905-1916.
Apache Software Foundation. (2016). AsterixDB. (The Apache Software Foundation) Retrieved 2019, from https:// asterixdb.apache.org/index.html
Apache Software Foundation. (2018). Apache Spark. (The Apache Software Foundation) Retrieved 11 27, 2019, from https://spark.apache.org
Apache Software Foundation. (2019). Apache Flink® — Stateful Computations over Data Streams. (The Apache Software Foundation) Retrieved 11 27, 2019, from https://flink.apache.org
Apache Software Foundation. (2019). Apache Hadoop. (The Apache Software Foundation) Retrieved 11 27, 2019, from https://hadoop.apache.org
Ben, M., & Marks, P. (2006). Out of the Tar Pit. BCS Software Practice Advancements.
Bedforshire. Bennett, R., Pickering, M., & Sargent, J. (2018, March). Inovations in Land Data Governance: Unstructured Data, NoSQL, Blockchain, and Big Data Analytics Unpacked. Retrieved April 1, 2018, from Land and Poverty Conference 2018: Land Governance in an Interconnected World: https://www. conftool.com/landandpoverty2018
Bennett, R., Pickering, M., & Sargent, J. (2019). Transformations, transitions, or tall tales? A global review of the uptake and impact of NoSQL, blockchain, and big data analytics on the land administration sector. Land Use Policy, 83, 435-448.
Brewer, E. (2000, July 19). Retrieved March 18, 2019, from Towards Robust Distributed Systems: https:// people.eecs.berkeley.edu/~brewer/ cs262b-2004/PODC-keynote.pdf
Brewer, E. (2012). CAP Twelve Years Later: How the “Rules” Have Changed. Computer, 45(2), 23-29. Brooks, F. P. (1987). No Silver Bullet: Essence and Accidents of Software Engineering. IEEE Computer, 20, 10-19.
Carey, M. J. (2019). AsterixDB Mid- Flight: A Case Study in Building Systems in Academia. 35th IEEE International Conference on Data Engineering, ICDE 2019. Macao.
Cockroach Labs. (2019). Cockroach Labs, the company building CockroachDB. (Cockroach Labs) Retrieved 11 28, 2019, from https://www.cockroachlabs.com
CockroachDB. (2018, March 30). The CockroachDB Architecture Document. (GitHub, Inc.) Retrieved August 8, 2019, from https://github.com/cockroachdb/ cockroach/blob/master/docs/design.md
Dinh, T. T., Wang, J., Chen, G., Ooi, B. C., & Tan, K.-L. (2018). Untangling Blockchain: A Data Processing View of Blockchain Systems. IEEE Transactions on Knowledge and Data Engineering, 30(7), 1366-1385.
Docker, Inc. (2019). Enterprise Container Platform Docker. (Docker, Inc.) Retrieved 11 29, 2019, from https://www.docker.com
El-Hindi, M., Binnig, C., Arasu, A., Kossmann, D., & Ramamurthy, R. (2019). BlockchainDB – A Shared Database on Blockchains. Proceedings of the VLDB Endowment, 12(11), 1597- 1609.
Eldawy, A., & Mokbel, M. (2015). SpatialHadoop: A MapReduce Framework for Spatial Data. 31st IEEE International Conference on Data Engineering. Seoul.
Facebook, Inc. (2019). RocksDB. (Facebook, Inc.) Retrieved 11 28, 2019, from https://rocksdb.org
Fauna, Inc. (2019). FaunaDB: A fundamental shift in database technology. (Fauna, Inc.) Retrieved August 10, 2019, from https://fauna.com/faunadb
Galić, Z., Mešković, E., & Osmanović, D. (2017). Distributed Processing of Big Mobility Data as Spatio-Temporal Data Streams. GeoInformatica, 21(2), 263-291.
Gartner, Inc. (2019). The Future of the DBMS Market Is Cloud. Stamford: Gartner, Inc.
Google, Inc. (2019, January 22). Cloud Spanner. (Google, Inc.) Retrieved August 10, 2019, from https://cloud.google.com/spanner/
Google, Inc. (2019). The Go Programming Language. (Google, Inc.) Retrieved 11 28, 2019, from https://golang.org
Grolinger, K., Higashino, W. A., Tiwari, A., & Capret, M. A. (2013). Data Management in Cloud Environments: NoSQL and NewSQL Data Stores. Journal of Cloud Computing: Advances, Systems and Applications, 2(22), 1-24.
Harizopoulos, S., Abadi, D. J., Madden, S., & Stonebraker, M. (2008). OLTP Through the Looking Glass, and What We Found There. Proceedings of the ACM SIGMOD International Conference on Management of Data, SIGMOD 2008. Vancouver, BC.
ISO. (2012). ISO 19152:2012 Geographic information — Land Administration Domain Model (LADM). Geneva: ISO.
Ito, J., Narula, N., & Robleh, A. (2017, March 9). The Blockchain Will Do to the Financial System What the Internet Did to Media. (Harvard Business Review) Retrieved January 2, 2020, from https://hbr.org/2017/03/theblockchain- will-do-to-banks-and-lawfirms- what- the-internet-did-to-media
Jinzhu. (2019). The fantastic ORM library for Golang. Retrieved from http://gorm.io
Kleppmann, M. (2015). A Critique of the CAP theorem. CoRR, abs/1509.05393.
Kleppmann, M. (2017). Designing Data-Intensive Applications: The Big Ideas Behind Reliable, Scalable, and Maintenable Systems. Sebastopol, CA: O’Reilly Media.
Linux Foundation. (2019). Production- Grade Container Orchestration. (The Linux Foundation) Retrieved 11 29, 2019, from https://kubernetes.io
Mahajan, P., Alvisi, L., & Dahlin, M. (2011). Consistency, Availability, and Convergence. Austin: University of Texas at Austin.
McSheery, F., Isard, M., & Murray, D. G. (2015). Scalability! But at what COST? 15th USENIX Workshop on Hot Topics in Operating Systems, HotOS XV.Kartause Ittingen.
Morpheus. (2017, February 28). Why Is This 30-Year-Old Website Architecture So Popular in 2017? Retrieved 2019, from https://www. morpheusdata.com/blog/2017-02- 28-shared- nothing-architecture
Muzammal, M., Qu, Q., & Nasrulin, B. (2018). Renovating Blockchain with Distributed Databases: An Open Source System. Future Generation Computer Systems, 90, 105-117.
Nathan, S., Govindarajan, C., Saraf, A., Sethi, M., & Jayachandran, P. (2019). Blockchain Meets Database: Design and Implementation of a Blockchain Relational Database. Proceedings of the VLDB Endowment, 12(11), 1539-1552.
NIST. (2011). The NIST Definition of Cloud Computing. Gaithersburg, MD: National Institute of Standards and Technologies.
NuoDB, Inc. (2019). NuoDB. (NuoDB, Inc.) Retrieved August 10, 2019, from https://www.nuodb.com
Ong, K. W., Papakonstantinou, Y., & Vernoux, R. (2015). The SQL++ Query Language: Configurable, Unifying and Semi-structured. CoRR, abs/1405.3631.
Ongaro, D., & Ousterhout, K. J. (2014). In Search of an Understandable Consensus Algorithm. 2014 USENIX Annual Technical Conference, USENIX ATC ‘14. Philadelphia.
Öszu, M. T., & Valduriez, P. (2020). Principles of Distributed Database Systems. Cham, Switzerland: Springer Nature.
Pavlo, A., & Aslett, M. (2016). What’s Really New with NewSQL? SIGMOD Record, 45(2), 45- 55.
Pritchett, D. (2008). BASE: An ACID Alternative. ACM Queue, 6(3), 48-55.
Roubini, N. (2018, October). Testimony for the Hearing of the US Senate Committee on Banking, Housing and Community Affairs On “Exploring the Cryptocurrency and Blockchain Ecosystem”. (United States Senate Committee on Banking, Housing, and Urban Affairs) Retrieved January 2, 2020, from https://www. banking.senate.gov/imo/media/doc/ Roubini%20Testimony%2010-11-18.pdf
Sharma, A., Schuhknecht, F. M., Agrawal, D., & Dittrich, J. (2018). How to Databasify a Blockchain: the Case of Hyperledger Fabric. CoRR, abs/1810.13177.
Stonebraker, M. (2012). New Opportunities for New SQL. Communications of the ACM, 55(11), 10-11.
Stonebraker, M., & Cetintemel, U. (2018). “One Size Fits All”: An Idea Whose Time Has Come and Gone. In Making Databases Work (pp. 441-462). New York/ San Rafael: ACM/Morgan & Claypool.
Stonebraker, M., Madden, S., Abadi, D. J., Harizopoulos, S., Hachem, N., & Helland, P. (2007). The End of an Architectural Era (It’s Time for a Complete Rewrite). Proceedings of the 33rd International Conference on Very Large Data Bases. Vienna.
van Steen, M., & Tanenbaum, A. S. (2017). Distributed Systems. CreateSpace Independent Publishing Platform.
Viotti, P., & Vukolić, M. (2016). Consistency in Non-Transactional Distributed Storage Systems. ACM Computing Surveys, 49(1), 19:1-19:34.
VoltDB, Inc. (2019). VoltDB. (VoltDB) Retrieved August 10, 2019, from https://www.voltdb.com
Yu, J., Zhang, Z., & Sarwat, M. (2019). Spatial Data Management in Apache Spark: The GeoSpark Perspective. GeoInformatica, 23(1), 37-78.
YugaByte, Inc. (2016-2019). YugaByteDB . (YugaByte, Inc.) Retrieved August 10, 2019, from https://www.yugabyte.com
Paper prepared for presentation at the “2020 World Bank Conference on Land And Poverty” The World Bank – Washington DC, March 16-20, 2020.











 (14 votes, average: 4.93 out of 5)
(14 votes, average: 4.93 out of 5)




Leave your response!